Google’s Bard بر اساس مدل زبان LaMDA است که بر روی مجموعه دادههای مبتنی بر محتوای اینترنتی به نام Infiniset آموزش داده شده است که اطلاعات بسیار کمی در مورد اینکه دادهها از کجا آمدهاند و چگونه آنها را دریافت کردهاند.
مقاله تحقیقاتی LaMDA 2022 درصدی از انواع مختلف دادههای مورد استفاده برای آموزش LaMDA را فهرست میکند، اما تنها ۱۲.۵ درصد از مجموعه دادههای عمومی محتوای خزیده شده از وب و ۱۲.۵ درصد دیگر از ویکیپدیا میآیند.
Google عمداً مبهم است که بقیه دادههای خراششده از کجا میآیند، اما نکاتی در مورد اینکه چه سایتهایی در آن مجموعه دادهها قرار دارند وجود دارد.
مجموعه داده Infiniset Google
Google Bard بر اساس یک مدل زبان به نام LaMDA است که مخفف مدل زبان برای برنامههای گفتگو است.
LaMDA بر روی مجموعه داده ای به نام Infiniset آموزش داده شده است.
Infiniset ترکیبی از محتوای اینترنتی است که عمداً برای افزایش توانایی مدل برای درگیر شدن در گفتگو انتخاب شده است.
مقاله تحقیقاتی LaMDA (PDF) توضیح می دهد که چرا آنها این ترکیب محتوا را انتخاب کرد:
“…این ترکیب برای دستیابی به عملکرد قوی تر در وظایف محاوره ای انتخاب شده است …در حالی که همچنان توانایی خود را برای انجام سایر وظایف مانند تولید کد حفظ می کند.
به عنوان کار آینده، میتوانیم بررسی کنیم که چگونه انتخاب این ترکیب ممکن است بر کیفیت برخی از کارهای NLP دیگر انجامشده توسط مدل تأثیر بگذارد.”
مقاله پژوهشی به گفتگو و گفتگو اشاره میکند، که املای کلمات مورد استفاده در این زمینه، در قلمرو علوم کامپیوتر است.
در مجموع، LaMDA روی ۱.۵۶ تریلیون کلمه “دادههای گفتگوی عمومی و متن وب از قبل آموزش داده شده بود.”
مجموعه داده از ترکیب زیر تشکیل شده است:
- ۱۲.۵% داده مبتنی بر C4
- 12.5% ویکیپدیا به زبان انگلیسی
- ۱۲.۵% اسناد کد از وب سایت های برنامه نویسی پرسش و پاسخ، آموزش ها و موارد دیگر
- ۶.۲۵٪ اسناد وب انگلیسی
- ۶.۲۵٪ اسناد وب غیر انگلیسی
- ۵۰% داده ها را از تالارهای گفتگوی عمومی باز می کند
دو بخش اول Infiniset (C4 و Wikipedia) از دادههای شناخته شده تشکیل شده است.
مجموعه داده C4، که به زودی مورد بررسی قرار خواهد گرفت، یک نسخه فیلتر شده ویژه از مجموعه داده Common Crawl است.
فقط ۲۵٪ از داده ها از یک منبع نامگذاری شده است ( مجموعه داده C4 و ویکی پدیا).
بقیه دادههایی که ۷۵% از مجموعه داده Infiniset را تشکیل میدهند، شامل کلماتی است که از اینترنت حذف شدهاند.
مقاله تحقیقاتی نمیگوید چگونه دادهها از وبسایتها بهدست آمده، از چه وبسایتهایی یا جزئیات دیگری درباره محتوای خراشیده شده بهدست آمده است.
Google فقط از توضیحات کلی مانند “اسناد وب غیر انگلیسی” استفاده می کند.
لغت “تاریک” به معنای زمانی است که چیزی توضیح داده نمی شود و عمدتاً پنهان است.
Murky بهترین کلمه برای توصیف ۷۵٪ از دادههایی است که Google برای آموزش LaMDA استفاده کرده است.
سرنخهایی وجود دارد که ممکن است تصور کلی از چه سایتهایی در ۷۵ درصد محتوای وب وجود دارد، اما ما نمیتوانیم به طور قطع بدانیم.
مجموعه داده C4
C4 مجموعه داده ای است که توسط Google در سال ۲۰۲۰ توسعه یافته است. C4 مخفف “Colossal Clean Crawled Corpus.”
این مجموعه داده مبتنی بر دادههای Common Crawl است که یک مجموعه داده منبع باز است.
درباره Crawl مشترک
Common Crawl یک سازمان غیرانتفاعی ثبت شده است که به صورت ماهانه در اینترنت می خزند تا مجموعه داده های رایگان ایجاد کنید که هر کسی بتواند از آن استفاده کند.
سازمان Common Crawl در حال حاضر توسط افرادی اداره میشود که برای بنیاد ویکیمدیا کار کردهاند، کارمندان سابق گوگل، بنیانگذار Blekko، و افرادی مانند پیتر نورویگ، مدیر تحقیقات Google و دنی سالیوان (همچنین از Google) به عنوان مشاور به حساب میآیند. .
C4 چگونه از Common Crawl توسعه مییابد
دادههای خام Common Crawl با حذف مواردی مانند محتوای نازک، کلمات زشت، lorem ipsum، منوهای ناوبری، تکراریسازی و غیره پاک میشوند تا مجموعه داده به محتوای اصلی محدود شود.
هدف از فیلتر کردن دادههای غیرضروری حذف ابهامات و حفظ نمونههای انگلیسی طبیعی بود.
این چیزی است که محققانی که C4 را ایجاد کردند، نوشتند:
“برای جمع آوری مجموعه داده های پایه خود، متن استخراج شده از وب را از آوریل ۲۰۱۹ دانلود کردیم و فیلتر فوق را اعمال کردیم.
این کار مجموعهای از متن را تولید میکند که نه تنها مرتبهای بزرگتر از بسیاری از مجموعههای داده مورد استفاده برای پیشآموزش (حدود ۷۵۰ گیگابایت) است، بلکه شامل متن انگلیسی نسبتاً تمیز و طبیعی است.
ما این مجموعه داده را “Colossal Clean Crawled Corpus” (یا به اختصار C4) دوبله می کنیم و آن را به عنوان بخشی از TensorFlow Datasets منتشر می کنیم…”
نسخه های فیلتر نشده دیگری از C4 نیز وجود دارد.
مقاله پژوهشی که مجموعه داده C4 را توصیف میکند، عنوان دارد، کاوش در محدودیتهای یادگیری انتقالی با تبدیل یکپارچه متن به متن (PDF).
یک مقاله تحقیقاتی دیگر از سال ۲۰۲۱، (مستند کردن شرکتهای متنی وب بزرگ: مطالعه موردی در Colossal Clean Crawled Corpus – PDF) ساختار سایت های موجود در مجموعه داده C4 را بررسی کرد.
جالب است که مقاله تحقیقاتی دوم، ناهنجاریهایی را در مجموعه داده اصلی C4 کشف کرد که منجر به حذف صفحات وبی که همتراز با اسپانیایی تبار و آمریکایی آفریقایی تبار بودند، انجام شد.
صفحات وب هم تراز شده اسپانیایی توسط فیلتر فهرست مسدود شده (کلمات فحش و غیره) به میزان ۳۲٪ از صفحات حذف شدند.
صفحات وب تراز شده آمریکایی آفریقایی با نرخ ۴۲% حذف شدند.
احتمالاً این کاستی ها برطرف شده است…
یک یافته دیگر این بود که ۵۱.۳٪ از مجموعه داده C4 شامل صفحات وب است که در ایالات متحده میزبانی می شدند.
در نهایت، تجزیه و تحلیل ۲۰۲۱ مجموعه داده اصلی C4 تأیید می کند که مجموعه داده تنها کسری از کل اینترنت را نشان می دهد.
تحلیل بیان میکند:
“تحلیل ما نشان می دهد که در حالی که این مجموعه داده بخش قابل توجهی از اینترنت عمومی را نشان می دهد، به هیچ وجه نماینده دنیای انگلیسی زبان نیست و طیف وسیعی از سال ها را در بر می گیرد.
>
هنگام ساختن یک مجموعه داده از یک اسکراپ از وب، گزارش دامنه هایی که متن از آنها خراشیده می شود برای درک مجموعه داده ضروری است. فرآیند جمعآوری دادهها میتواند منجر به توزیع بسیار متفاوت دامنههای اینترنتی نسبت به آنچه انتظار میرود، شود.” sss2_sllo_o mmh-90-wrap”>
آمار زیر در مورد مجموعه داده C4 از دومین مقاله تحقیقاتی است که در بالا پیوند داده شده است.
۲۵ وب سایت برتر (براساس تعداد نشانه ها) در C4 عبارتند از:
- patents.google.com
- en.wikipedia.org
- en.m.wikipedia.org
- www.nytimes.com
- www.latimes.com
- www.theguardian.com
- journals.plos.org
- www.forbes.com
- www.huffpost.com
- patents.com
- www.scribd.com
- www.washingtonpost.com
- www.fool.com
- ipfs.io
- www.frontiersin.org
- www.businessinsider.com
- www.chicagotribune.com
- www.booking.com
- www.theatlantic.com
- link.springer.com
- www.aljazeera.com
- www.kickstarter.com
- caselaw.findlaw.com
- www.ncbi.nlm.nih.gov
- www.npr.org
اینها ۲۵ دامنه برتر سطح بالا در مجموعه داده C4 هستند:
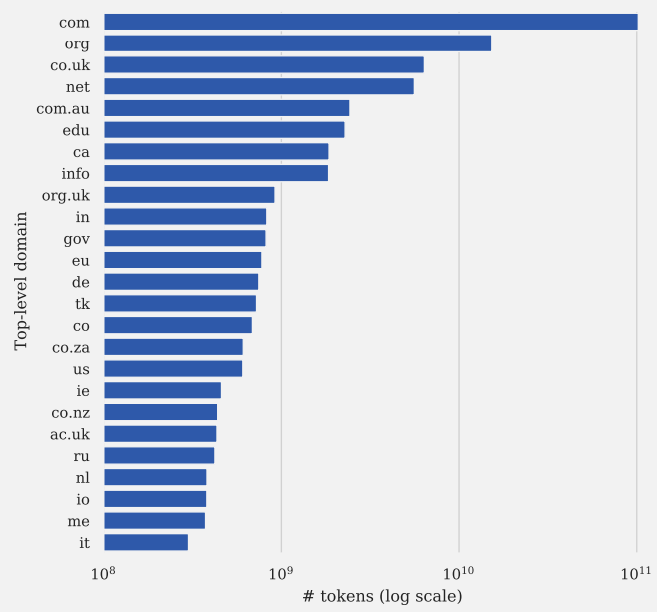 عکس از Documenting Large Webtext Corpora: مطالعه موردی بر روی پیکره خزنده پاک عظیم
عکس از Documenting Large Webtext Corpora: مطالعه موردی بر روی پیکره خزنده پاک عظیماگر علاقه مند به کسب اطلاعات بیشتر در مورد مجموعه داده های C4 هستید، توصیه می کنم مستندسازی را مطالعه کنید. Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus (PDF) و همچنین مقاله تحقیقاتی اصلی ۲۰۲۰ (PDF) که C4 برای آن ایجاد شد.
داده های دیالوگ از تالارهای گفتمان عمومی چه می تواند باشد؟
۵۰٪ از دادههای آموزشی از «دادههای گفتگو از انجمنهای عمومی میآیند.»
این تمام چیزی است که مقاله تحقیقاتی LaMDA Google درباره این دادههای آموزشی میگوید.
اگر بخواهیم حدس بزنیم، Reddit و سایر انجمنهای برتر مانند StackOverflow شرطبندی مطمئنی هستند.
Reddit در بسیاری از مجموعه دادههای مهم مانند مجموعههایی استفاده میشود که توسعه یافته توسط OpenAI به نام WebText2 (PDF)، یک تقریب متن باز از WebText2 به نام OpenWebText2 و WebText-like ( PDF) مجموعه داده از سال ۲۰۲۰.
Google همچنین یک ماه قبل از انتشار مقاله LaMDA جزئیات دیگری از مجموعه دادههای سایتهای گفتگوی عمومی را منتشر کرد.
این مجموعه داده که حاوی سایت های گفتگوی عمومی است MassiveWeb نامیده می شود.
ما حدس نمی زنیم که از مجموعه داده MassiveWeb برای آموزش LaMDA استفاده شده باشد.
اما این شامل یک مثال خوب از آنچه Google برای مدل زبان دیگری که بر گفتگو متمرکز است، انتخاب کرده است.
MassiveWeb توسط DeepMind که متعلق به Google است ایجاد شده است.
برای استفاده توسط یک مدل زبان بزرگ به نام Gopher طراحی شده است (پیوند به PDF از مقاله تحقیقاتی).
MassiveWeb از منابع وب محاوره ای استفاده می کند که فراتر از Reddit هستند تا از ایجاد سوگیری نسبت به داده های تحت تأثیر Reddit جلوگیری کند.
هنوز از Reddit استفاده می کند. اما همچنین حاوی داده های خراشیده شده از بسیاری از سایت های دیگر است.
سایت های گفتگوی عمومی موجود در MassiveWeb عبارتند از:
- فیس بوک
- Quora
- یوتیوب
- متوسط
- StackOverflow
باز هم، این نشان نمیدهد که LaMDA با سایتهای بالا آموزش دیده است.
این فقط برای نشان دادن آنچه Google میتوانست استفاده کند است، با نشان دادن مجموعه دادهای که Google روی آن تقریباً همزمان با LaMDA کار میکرد، مجموعهای که حاوی سایتهایی از نوع انجمن است.
۳۷.۵% باقیمانده
آخرین گروه از منابع داده عبارتند از:
- ۱۲.۵% اسناد کد از سایت های مرتبط با برنامه نویسی مانند سایت های پرسش و پاسخ، آموزش ها و غیره؛
- ۱۲.۵% ویکی پدیا (انگلیسی)
- ۶.۲۵٪ اسناد وب انگلیسی
- ۶.۲۵% اسناد وب غیر انگلیسی.
Google مشخص نمیکند چه سایتهایی در دسته سایتهای پرسش و پاسخ برنامهنویسی قرار دارند که ۱۲.۵٪ از مجموعه دادهای را تشکیل میدهد که LaMDA روی آن آموزش دیده است.
بنابراین ما فقط می توانیم حدس بزنیم.
Stack Overflow و Reddit گزینههای واضحی به نظر میرسند، به خصوص که در مجموعه داده MassiveWeb گنجانده شدهاند.
چه سایت های “آموزش” خزیده شدند؟ ما فقط میتوانیم حدس بزنیم که آن سایتهای «آموزش» ممکن است چه باشند.
این سه دسته آخر محتوا را ترک میکند که دو دسته از آنها بسیار مبهم هستند.
ویکیپدیای انگلیسی زبان نیازی به بحث ندارد، همه ما ویکیپدیا را میشناسیم.
اما دو مورد زیر توضیح داده نشده اند:
صفحات وب به زبان
انگلیسی و غیرانگلیسی شرح کلی ۱۳% از سایت های موجود در پایگاه داده هستند.
این همه اطلاعاتی است که Google در مورد این بخش از دادههای آموزشی ارائه میدهد.
آیا Google باید در مورد مجموعه داده های استفاده شده برای Bard شفاف باشد؟
برخی ناشران از اینکه سایتهایشان برای آموزش سیستمهای هوش مصنوعی استفاده میشود احساس ناراحتی میکنند، زیرا به نظر آنها، این سیستمها در آینده میتوانند وبسایتهایشان را منسوخ و ناپدید کنند.
این که آیا این درست است یا نه، باید مشخص شود، اما این یک نگرانی واقعی است که توسط ناشران و اعضای جامعه بازاریابی جستجو بیان شده است.
Google در مورد وبسایتهایی که برای آموزش LaMDA استفاده میشوند و همچنین اینکه چه فناوری برای خراش دادن وبسایتها برای دادهها استفاده شده است، بهطور ناامیدکنندهای مبهم است.
همانطور که در تجزیه و تحلیل مجموعه داده های C4 مشاهده شد، روش انتخاب محتوای وب سایت برای آموزش مدل های زبان بزرگ می تواند کیفیت مدل زبان را با حذف جمعیت های خاص تحت تاثیر قرار دهد.
آیا Google باید در مورد سایتهایی که برای آموزش هوش مصنوعی آنها استفاده میشود شفافتر باشد یا حداقل یک گزارش شفافسازی آسان درباره دادههای استفاده شده منتشر کند؟
تصویر ویژه توسط Shutterstock/Asier Romero
